信息检索引入: 数据结构
信息检索:根据用户输入信息(query)返回文档检索列表(ranked list),像是各种搜索引擎和信息查询系统都是常见的信息检索系统。
Boolean model 是老师引入信息检索的例子。 使用 NOT/AND/OR 等 boolean 操作符搜索符合条件的文档。 如果你有在大一/大二听过UCD的 OneSearch/图书馆系统使用教程/google scholar 这种信息检索帮助教程的话,那个中就叫了简单的Boolean model 检索文档的方式,这个是最广泛支持的搜索方式之一。
例子:
- 文档中包含有 Anony这个词
- 找文档中有 cat 但是没有 dog 的文档 特点:没有ranking,没有部分匹配
实现: 一个最简单的想法就是将所有的要检索的词(terms)和所有文档做一个矩阵,0无1有。然后按行(每一个term)得出一个 vector ,之后用 boolean 操作符计算就好了。
| terms \ documents | 语文书 | 数学书 |
|---|---|---|
| 函数 | 0 | 1 |
| 李白 | 1 | 0 |
问题就是当文档量上来之后就出现了问题: terms 和文档构成的矩阵的数据将远大于可能含有的 “1” 的数量形成一个稀疏矩阵浪费空间。
简单计算: 一百万 documents,每个一百字。 我们假设一共有50000 个不同的terms(给的挺少)那么矩阵就是一个 50k x 1000k的大矩阵,但是就算所有文档中的字都不重样,我们总共也就有1000k x 100 个字符,全部都是1 的情况下大部分矩阵空间也都是空的。
介绍!Inverted Indexing! 将文档数据整理为一个更方便的数据结构的过程就叫 Indexing。 在这里使用的是一个 有序 list 结构,将文档序号 list 附带到 terms 后。 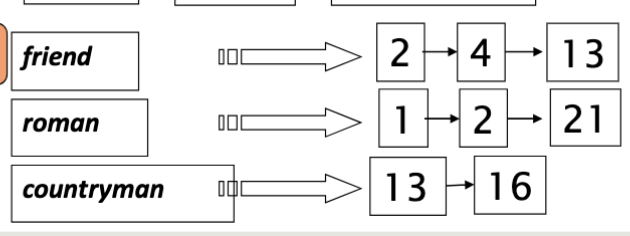
Index 步骤:
- 将输入的文档转化为 Token 序列
- 将得出的 terms 按字母顺序排序
- 根据排序出的构成一个字典
- posting:将构建文档的序号 list 有序的排列到 字典对应的 terms 后面,构成一个有序 list
AND 检索算法:O(X+Y)
两个 list 索引a/b从头开始, 一个空列表 answer:
if a < b -> a++ if b < a -> b++ if a == b -> 对应序号加入answer,ab++
Query 优化 通过排序 OR 和 AND 操作,可以优化操作,减少merge次数: AND 在较短的list之后可以直接完结,而不用走完整个较长的list。
Skip Pointer: 通过在某些节点加入指针指向后面的节点可以节省检索过程。
对于实现来说就要多考虑一下指针节点的判断问题,但是相比于多判断这几下的性能消耗,skip pointer 的优化是显著的
Preprocessing
Tokenization 是将语句转化为token object的过程
Normalization:将每一个token转化为标准形式:小写,去掉标点("-"),去掉 Stopwords:出现频率高但是不够unique的词,比如许多连词等。
NOTE
stopwords 过于常见而对于文章的语义贡献不大。区分度不够大进而无法在文档搜索中作出贡献 但是在处理文章的时候如果直接去掉所有stopwords就会出现搜不到"to be or not to be"这种情况,所以也要分情况处理
之后是对在 Normalization 和 Tokenization 过程中的难点 问题:
- 连字符/多词词组/非空格分割的语言(中文/日文)/数字的分割不唯一。
- 写错字导致无法查询。
- 对于同义词的处理(car能不能搜出来有automobile的document)
我们已经有了一些方法来处理这些问题,但是这些方法不是万能的,大多都是trade off的。 比如对于错字,我们可以用发音方式匹配:大多数错字都是拼错但是发音不变。 同义词:将所有的同义词通过词库(整理出的词关联库)的方式全部加入query中,直接避免了同义词问题。
Stemming:通过对一个词去掉它的suffix/prefix来得到一个更广泛的模糊查询,快但是不准确。老师课上给的例子以及在习题课的库是 porter's stemming 算法,这个算法是最广泛应用的算法之一。 stemming 操作的一个原则:对于每一个对文档动的操作,应该也对 query 做。(不然你咋查呢?)
lemma:通过词汇学来还原一个词语到基础态来保证模糊查询,慢但是准确
Phrase queries(词组查询)
之前的 term/docs 对不足以处理比如像是“Stanford university”这样的组合词的检索,因此需要新的技术来
一个很简单的想法是做一个biword terms:也就是直接存储“Stanford university”这个词组
那么怎么查一个三字词组? "go Stanford" And "Stanford university"这种查法会出现假阳性。“go Stanford”和"Stanford university" 之间可能隔了很远,没有语义上的关联了,只是恰巧出现在这个文档中。 然后用biword terms这种方式会让字典会变很大。
介绍,positional indexes!
将term/docs对拓展为term/docs/(docs*positionList),将terms在文件内的位置也记录下来 这样可以用来帮助检索过程:搜索“to be or not to be”,此时两个be距离为4,这时筛选出两个be相聚距离为4的position有助于缩小范围 怎么检索三字词呢?
通过检查terms 位置关系可以找到三字词,比如new york City york = new +1 city = york +1
现在混合使用biwords和positional index
Vector space model
过去的 boolean model 中只有有无,模糊性不够 vector space model 将 queries 和documents 放在了一个N-dimensional space 中,用代数方法算出近似性。 也就是说每一个document都是一个模型中的向量,它其中的terms用非零正数表示,一个document 由所有terms组成,不含有的terms为0.
similarity score是由两个document/query向量的相近程度计算的,由sim(q,d)表示query q和document d 这时候会返回一个ranked list,最高的就是最相近的。
cosine similarity:
这个的基本思想就是两个vector之间的角度越近,说明两个term越相近。那么我们可以用一个很基本的算cos的公式得出它的值:
document collection中含有不同的terms量就是dimension数
要表示整个model,我们需要一个可用的方式将document转化为向量。最常用的方式是使用TF-IDF值来作为term weighting。 TF := Term Frequency IDF := inverse Document Frequency 这个方法本质就是结合了这两个权重思想得出的方法: -> 词在当前文档中出现的越多:越重要 -> 词在整个文档组中越稀有: 越重要(这也代表一个term在整个文档组中都是同一个值)
Term frequency:term i 在文档j中的TF
Inverse Document Frequency:term i 的 IDF
TF-IDF得出权重值
向量空间方式总结
TF-IDF的优点: 这个文档中terms越多的给的权重越高,同时也确保了在整个文档中越稀有越好
如何构建一个向量空间:
- Read documents - 把整个文档读进来
- Tokenization - 把文档全部转换成一个个terms
- Remove stopwords
- Stemming / Normalization
- 转化为标准形式
- Build index - 将文档序号加在terms后,做成一个inverse list
- term → postings list
- Compute TF-IDF - 计算出每一个terms的IDF - 计算出terms在每一个文档中的TF - 计算出weight
- Receive query - 在收到用户查询的query时将query预处理后转化为vector
- Retrieve results - 计算相似度 - 返回一个有序的rank list
Vector Space Model 优缺点
优点:
- 支持 partial match
- 支持 ranking,使用cosine silimarity的方式
- term weighting 提升搜索表现(准确性提升) 缺点:
- 假设 term 独立
- 忽略词序
例子:BM25
BM25(Best Matching 25)是经典 Information Retrieval 中最重要的概率排序模型之一,也是现代搜索系统中极其常见的 baseline ranking function。
它建立在 Probabilistic IR Model 的思想上,同时吸收了 TF-IDF 的优点,因此通常比传统 TF-IDF 有更好的检索表现。
核心思想
BM25 认为文档是否与 query 相关,主要受三个因素影响:
Term Frequency (TF)
query 中的词在文档中出现越多,通常越相关。Inverse Document Frequency (IDF)
如果某词只出现在少数文档中,则它更有区分能力。Document Length Normalization
长文档天然包含更多词,因此不能仅因为文档长就获得更高分数。
在BM25中的TF和我们之前的TF不太一样,之前的TF除以最常见的term的frequency,实现了normalization。但是在BM25中使用
对于BM25中的normalization,它是这样一个想法的: 如果短文档中有elephant,那么它很有可能是关于elephant的,如果长文档中只有一个elephant,那么它很有可能不是关于elephant的。
因此需要根据文档长度调整 TF 的贡献。
若:
- 文档长度 > 平均长度 → 降低得分
- 文档长度 < 平均长度 → 相对提高得分
对于IDF,因为BM25是一个实验性模型,主要考虑的是验证理论,因此采用的IDF也有所不同:
完整BM25的sim公式:
讲解: 首先是前面的求和部分:
这一部分是前面讲的TF部分,这个1+k是一个经验参数,由工程实际得出。上面的数字会影响得出的分数,根据实际使用中
长度归一化部分:这一部分使得下方的k和长度有关,由长度控制,因此是k乘以一个跟长度相关的公式
IDF部分:
Evaluation
如何评估(Evaluate)一个IR系统
对于一个IR系统来说,系统表现可以从很多个维度评估:
- Processing: 系统回复速度有多快?系统资源使用效率有多高?
- User experience: 用户满意度如何?
- Search: 系统返回的信息对用户有多有用? <- 重点
本课程主要聚焦于Search部分: 在信息系统的评估中我们使用很多Matrics(指标)来评估系统:
- Precision/Recall
- Precision @ n/R-precision
- Mean Average Precision (MAP)
- bPref
- NDCG
整个评估流程是在 Cranfield Paradigm 下进行的,也就是对于输入 query 检测 IR 系统返回的 Documents 以及相关的 relevant 集合是提前确定好的。 整体模型中可以分为三个集合: Collection: 全集,也就是数据库 Relevant set: 由人类专家确定出的有关集合,也就是标准答案 Retrieved set: Query输入到IR系统中返回的解集 我们可以比较 Relevant 和 Retrieved set来得出各种Matrics的结果。
NOTE
在现实中返回的一般不是一个集合,而是一个Ranked List, 因此对IR系统的评估也变成了对这个Ranked List的质量的评估
Precision 和 Recall 是最广泛使用且基础的评价指标: Precision 代表你返回的结果有多“准” Precision :
进阶指标
基础指标不够用了,我们要引入新的指标来评估系统,我们希望能用一个数字(Single-value matrics)来评估整个系统.因此在这节课我们引入了几个新的基于precision思想的指标 也就是 P@n / Precision @ n 和 R-precision 和 MAP
P@n 这个指标代表的是只看前 n 个结果的 precision。常用在评估网络搜索结果。
这个指标最大的问题是它非常依赖于relevant的数量:如果relevant总数便小于n的量那么久不可能得到高分:比如总共就三个relevant但是要返回10个结果,那么最好也就是0.3。
那么一个明显的改进就是每次只看等同于relevant总量的结果,得到了 R-precision 指标:
Mean Average Precision (MAP) 在很长时间是最常用的衡量一个IR系统的指标,它基于Precision,但是做了一些改进: 首先它是由多个query查询取平均的来的,每一个query都需要做一个AP指标,接下来对AI指标取平均就是MAP。
Rel = 5 个 relevant 文档
返回值:
Rank: 1 2 3 4 5 6 7
Doc: R N R N N R R
第一步找relevant位置:1, 3, 6, 7
P@1 = 1/1 = 1.0
P@3 = 2/3 = 0.67
P@6 = 3/6 = 0.5
P@7 = 4/7 ≈ 0.57
接下来算平均值
AP = (1.0 + 0.67 + 0.5 + 0.57) / 5 //注意这里除以的是总Rel而不是出现的rel数前面的指标都是在Cranfield paradigm之下的,对于小集合来说Cranfield paradigm是完美的,但是对于我们不好确定relevant集合的大信息系统,我们就会出现不完全评估(Incomplete judgment),也就是会有一些文档没有被判断过是否相关。在这种情况下我们需要一个指标可以评估这种系统。传统方法也是最简单的方法就是将所有 No-judged document 作为 Non-relevant 加入系统,这种方法会严重稀释整个文档,降低系统评分。 因此我们引入了bpref,它是large-scale IR系统中常用的一个指标。 bpref (Binary Preference) 的想法是直接忽略所有未评估的文档,只看确定相关/不相关的文档。如果relevant 排在 non-relevant 前面 -> 好 , relevant 在 non-relevant 后面 -> 不好
R = 4(总共有4个 relevant 文档)
Rank: 1 2 3 4 5 6 7 8 9 10 11
Doc: N R U R U N N N R N R
N -> Non relevant
R -> relevant
U -> Unknown
第2个 → R
第4个 → R
第9个 → R
第11个 → R
根据公式:每个 R 的贡献 = 1 - (前面 N 的数量 / R)
1. R -> 前面共有1个N,总共有4个R -> 1 - (1/4) = 0.75
2. R -> 前面共有1个N,总共有4个R -> 1 - (1/4) = 0.75
3. R -> 前面共有4个N,总共有4个R -> 1 - (4/4) = 0
4. R -> 前面共有4个N,总共有4个R -> 1 - (4/4) = 0
计算平均值 bpref
bpref = (0.75 + 0.75 + 0 + 0) / 4
= 1.5 / 4
= 0.375NOTE
与前面介绍过的所有算法相比,bpref在不完整评估的情况下表现更好。 就目前<截至第7周>我们学的Matrics中只有bpref是针对Incomplete judgement的,其他的评价指标都是在优化Complete下的表现。
Binary preference顾名思义就是将所有的文档简单分为relevant和非relevant,但是实际上在一文档系统中文档和query之间的关系不止是有无联系,更进一步还有文档联系程度的区别。有的文档联系深,有的文档联系较浅,也就是说我们对于文档关系的划分不止是简单的定性了,而是要定量了,这时候我们需要一个更成熟的评价体系。
Normalised Discounted Cumulated Gain (NDCG) 目标是
- 将相关的文件置于不相关的文件之前 (并非改进)
- 将相关性高的文件置于不相关的文件之前 (前面的Matrics都是将相关性一视同仁的) 的系统得分高。
它集合了三个评价维度: Gain(文件相关性权重), Discount(位置衰减,惩罚靠后的结果), Normalization(归一化)。
为什么需要归一化?因为DCG本身没有标准,如果我们的评分需要比较,那么就需要一个统一的方式来划分标准。 那么我们怎么定这个标准呢?通过将它和最优解比较就行。
因此我们第一步就要先给所有的文件相关性打分:给每一个document得出自己的相关性级别。构建出 graded relevance judgments 集合。
得到之后我们最简单的方式就是先把所有的加起来,根据Ranked list的顺序从小到大累加,得到Cumulated Gain ,每个位置的CG就是它之前的加起来。
为了目标我们要引入位置惩罚 Discount, 因此我们将document除以log(rank)得到它的discount之后的值,得到减益
最后只要给他归一化(变到0到1区间)就行了。那么怎么归一化呢? 这时候引入了Ideal DCG(理想情况), 也就是把所有文档按 relevance 从高到低排的DCG
最终
- 排序位置越前越好
- 高相关 > 低相关
- 整体质量和最优解的比
Rank: 1 2 3 4 5
Rel: 3 2 3 0 1
Step 1: 写出 Gain 向量
G = (3, 2, 3, 0, 1)
Step 2: 计算 DCG
DCG[1] = 3
DCG[2] = 3 + 2/log2(2) = 5
DCG[3] = 5 + 3/log2(3) ≈ 5 + 1.89 = 6.89
DCG[4] = 6.89 + 0 = 6.89
DCG[5] = 6.89 + 1/log2(5) ≈ 6.89 + 0.43 = 7.32
DCG ≈ 7.32
Step 3: 构造 Ideal 排序
按 relevance 排序:
(3, 3, 2, 1, 0)
Step 4: 计算 IDCG
IDCG[1] = 3
IDCG[2] = 3 + 3/log2(2) = 6
IDCG[3] = 6 + 2/log2(3) ≈ 7.26
IDCG[4] = 7.26 + 1/log2(4) = 7.76
IDCG[5] = 7.76 + 0 = 7.76
IDCG ≈ 7.76
Step 5: 计算 NDCG
NDCG = DCG / IDCG
≈ 7.32 / 7.76
≈ 0.94NDCG的一个变种是NDCG@n,也就是取Ranked list前n个计算。
NDCG的特点:
- 将Rank 和 相关性结合起来了
- 在任意一个rank上可以得出结果,并且不需要知道recall (relevant集合)
- NDCG@n只考虑n那个点上的数值,而忽略再往后的东西。
- 对排在后面的相关文档给予更小的权重
学完了这些指标之后我们应该用哪个呢? 首先在complete judgement集合中我们能用几乎所有指标计算。 每个指标都有自己的优缺点,我们要权衡利弊 实际上每个系统都是用很多指标共同评估的,没有只用一个的理由
- MAP可以很好的反应整体性能,因为它对多query做了平均
- 如果数据标注不完整那么就用bpref
- 对于搜索引擎这种IR系统,用户多只关注前几个结果,适用P@n
- 如果有相关性等级那就用NDCG,它也是长期得到推崇的指标。
现代IR系统
在之前我们学到的都是经典信息系统的方法,或者说组件。 总结一下之前的东西: 我们学了
- What Information Retrieval is
- How indexes are built
- Retrieval models:
- Boolean Model
- Vector Space Model
- BM25
- Evaluation methods
一个经典信息系统处理信息的流程是 ![[信息检索2经典pipeline.png]]
经典系统的问题:
- 词汇不符: 用户输入词和系统里查的词不一定一样
- 只查字,无链接跳转查询: 经典IR系统只识别字,在类似网络查询这样的查询环境中不查找链接就是问题。
- 没有用到现代的AI技术,机器学习/NLP/深度学习/LLM 都没用上
- 速度要快
现代的IR系统一般会由多个检索阶段组合而成,整体上可以看作从粗筛到细筛的流程,使用简单的模型筛选较多的文档,形成较小候选池之后用更复杂的模型筛选。
![[信息检索3现代pipeline.png]]
这种情况下,前期筛选的recall就更为重要了,因为筛掉的文档就不会再被找回,找多了复杂模型能挑出去,找少了就没办法了。
- Early Retrieval → Recall 优先
- Final Ranking → Precision 优先
现代主要采用两个办法来增加recall: query expansion 和 pseudo-relevance feedback
Query expansion 通过将所有可能有关的词加入搜索 query 中来提高命中率: 比如搜索“航空”时自动将“航天”关键词加入搜索,以此来增大命中范围。在常规实现中一般会根据词根将所有词根相关的都放进去,同时也可以采用人工制作的语料库(manually-created thesaurus: WordNet),由像是wikipedia这种本身相关的知识库网站生成的语料库(automatically-created thesaurus)等。
如果User能够告诉我们哪些文档是有关的,哪些是无关的,那我们就可以改进IR系统了,但是用户永远不会这么干。
我们使用 Pseudo-Relevance Feedback 来模拟用户操作, 进而改进query。取前k个文档分析,根据文档结果来改进terms的权重,然后再重新用改进后的query进行一次查找。 它所反映的思想是相关度最高的几个文档大概率是relevant的,因此我们通过分析这些文档中的terms改进我们的query,来涵盖更多相关的文档。 缺点:query drift(查询漂移):如果在前几个文档中就有点错,那么经过提炼更改权重之后搜索就会更加错。
接下来仅作简单介绍,老师说会在剩下的课细致的介绍现代IR系统组件
在使用BM25和QL简单搜索完后,Fusion可以将多个模型得出的结果合并,并(hopefully的)得出一个更好的list。可以通过不同模型给document打的分/不同模型得到的ranked list/根据过往表现得出的概率来合并list。
在完成简单排序之后,我们使用Learn to rank(机器学习排序) 使用机器学习来给这个list 重排序。每一个我们输入到LTP的信息都是机器学习领域中的Feature
文本型feature
- Term occurrence / non-occurrence
- Term frequency
- Inverse Document Frequency
- Document Length
- Term Proximity
非文本型Features - PageRank
- URL Depth
- Document Quality
- Readability
- Sentiment
- Query Clarity
NOTE
其中PageRank技术是谷歌搜索引擎成功的要素之一: 一个document被视为重要的: 很多document指向这个document 或 很多重要的document指向这个document
Neural Language Models(神经网络语言模型,比如BERT): 使用基于深度学习LLM来处理文档和文字,简单来说它们理解文字在文件之中的含义,用密集向量(dense vector)来储存这些信息。
更进一步 Retrieval Augmented Generation 技术。也就是IR系统首先先找到相关文档,LLM在其中找到query的答案,做 citation 并返回答案. 其实就是简单的IR + LLM的组合
总结一下就是经典的IR系统相比于现代IR系统有局限性,一些技巧可以提升IR系统性能,但是因为总数据大,回复时间就很重要。现代IR系统是组合系统。IR系统在RAG系统中很重要,可以有效提升LLM内容的准确性。
这个周的内容是展开描述现代IR系统的Relevance Feedback 和 Query Expansion
这两个内容主要处理的是 vocabulary mismatch: 只有在文档中有exact 符合的terms 才会被找到。
Relecance Feedback
这代表用户参与进信息查找过程来优化最终结果。 比如用户回复最初返回的documents list的相关性,然后系统根据这个结果优化内容。 详细流程:
- 用户输入 query
- 系统返回初始结果
- 用户标记 relevant / non-relevant
- 系统重建 query representation
- 再次检索
对于这种用户反馈方式,Rocchio Algorithm 可以有效的优化query,让他接近相关set。
Rocchio 算法
对于所有向量set来说,它们有一个质心:
尽管我们得不到relevant/non-rel的质心,但是根据用户结果得出用户给的rel/non-rel集合质心是可以的,我们就用这个来模拟。
解释公式: q0代表原始query向量,第二项代表relevent 集合质心,第三项代表non-rel集合质心,前面的为参数,通过设计不同参数来影响向量移动权重。这样我们就可以在用户参与的情况下优化query了。
限制:用户一开始的搜索不能偏离太远,如果偏离太远导致初始结果中不含有有效答案,那么就无法逼近了。 不能有效解决 拼写错误 / 词义不符 (apple是科技公司和水果) / 跨语言IR
我们也默认relevant 结果是相似的,实际上不一定。Rocchio算法会把query往一个方向(relevant set 的质心)推,但比如在面对一个 query 搜索两件事(在中国踢球的UCD球队)时,在向量空间中relevant 结果是分散的,这会让算法失效。 类似的会造成relevant分散的情况有:
- 一个 query 多件事
- 使用同义词(astronaut vs cosmonaut)
- 使用过于广泛的词(felines(猫科))
pseudo-relevance feedback(伪反馈)
这一切的前提是用户给反馈。但用户不会给回馈,因此我们引入: pseudo-relevance feedback, 模拟用户的反馈. 核心思想就是假设 top-k ranked docs 是 relevant,然后自动执行 relevance feedback。 流程:
- 用户 query
- 初次检索
- 取 top-k docs
- 假设它们 relevant
- 提取关键词 / 修改 query
- 第二次检索
Implicit Feedback(隐式反馈)
系统通过行为推测文档相关性。
例如:
- 点了哪个结果
- 页面停留多久
- 浏览结果页多久
Query Expansion(查询扩展)
通过将terms 加入 query 来增加命中范围,减少mismatch。 通过匹配更多document 来增加recall。
有automatically 和 interactively两种形式: inter : 类似google 搜索那种你输入一个词出来后面的词的添加方式
palm ->
palm tree
palm phone
palm handauto:像是PubMed搜索引擎(医疗资料)会自动添加关联词来增大命中率
cancer ->
cancer + cancerous + neoplasms + cancers + ...那么系统该怎么知道要加哪些词呢?
- Thesaurus(词库) 这些词库由人工维护,记录关联词,优点:可靠 缺点:难以维护
- Automatic Thesaurus (自动生成词库) 从类似维基百科之类的关联性资料库中统计生成的词库,记录词与词出现的联系,比如truck经常和car出现,eat apple/prepare apple 得出 eat 和prepare有关联,由此得出的词库。 由于多词义词很多,用法也很多,因此得到的有些关联是无用的,需要排除。
- Word Embeddings(词义关联) 向量空间中的词可以通过计算similarity来得出相似性,相近的词被视为有关
- Query Log Mining(日志法) 搜索palm的很多人后来搜索了palm oil,记下来
很明显,QE在增加recall的同时降低了Precision
TSV(Term Selection Value)
这是结合了 PRF 和 QE 的方法 步骤
- 初次检索
- 假设 top-k relevant document
- 将这些文档中有最高Term Selection Value 的 terms 加入 query (数量可变,会影响表现)
- 第二次检索 有很多种计算TSV的方法,这里给的是一个例子
其中 t 是 term kt 是前k个文档中t的数量 idft 是t的IDF,词稀有度 当前文档高频出现 + 有区分度 的词更好
第二次检索的时候我们可以使用BM25计算rank了
两种方式:
- 无权重:原query和新query词全部平等进入bm25打分
- 有权重:Score = 原词BM25 + β × 扩展词BM25 β一般小于1,影响新词权重。
总结:QE增加Recall, 使用人工词库更好,但是维护贵又麻烦。因此我们用一些自动化手段。
Fusion
Fusion统合了多个评分标准,通过将多个不同 IR 系统 / Retrieval Model 的结果合并,
得到一个比单独系统更好的 ranked list (Hopefully) 。
对于一个输入,多个IR系统返回多个list,经典 Fusion 系统将他们融合成一个list。 而正如之前现代信息系统的介绍一样,fusion在现代的信息系统中承担了组合子系统结果的位置。 ![[信息检索现代pipelineFusion.png]] 在讨论Fusion之前有一个很重要的概念 Overlap
- Disjoint Database 数据库内的文档不重复,也就是一个文档最多出现在一个数据库内。分布式IR常常使用的是Disjoint的。在这种Database中的Fusion 常被称为 collection fusion。
- Identical Database: 所有IR系统筛选的原始文档都是一样的,因此文档常常出现在多个result集合中,出现在多个集合也被视为文档相关性高的一个表现。一个文档出现在多个文档被称为data fusion是本节重点
- Overleaping Database: IR系统使用不同版本的数据库,document 可能出现在多个数据库。 这个是最难处理的情况,一个IR系统不返回文档有可能是因为分不高,也有可能是因为文档不存在。
Fusion 中会存在的三个现象:
- Skimming Effect: 最顶上的一般是好的
- Chorus Effect: 多个系统认为好一般是好的
- Dark Horse Effect: 文档在某个系统特别强或者特别弱 Skimming Effect 在所有的Fusion系统中都被采用 对于非collection fusion 来说 Chorus effect是常被考虑到的,但是因为在collection fusion中document 不会出现在别的IR系统中,这个就没有影响。 尽管Dark horse effect存在,但是因为难以辨别黑马,因此在构建IR系统时大多不考虑。
Fusion 分类:
- Rank-based
- Score-based
- Probability-based
Rank
这种Fusion方式只看document的rank,不看所谓的score。因此适用于不返回score的IR系统。 一个最简单的例子就是 Interleaving 方式。 也就是每一个IR系统取一个,然后再取下一个,如果遇到取过的就跳过,直到填满列表。 这种不做区分顺序取的方式会导致好的IR系统被坏IR系统的结果污染 Borda Fuse 通过将result按照rank赋值:第一名c分,第二名c-1分以此类推,最后将所有的结果整合起来,得到一个ranked list。 Reciprocal Rank Fusion
是一个现代流行的方式
- R是Result list集合
- r(d):文档在某 result set 的 rank
- k:经验参数(通常 60)
并没有给出思想和理由,基本上就是rank大就小,rank小就大吧
Score
使用IR系统给出的score来进行排序 最简单也是最经典的方式是CumbSUM,也就是将所有IR系统返回的分数简单相加 尽管算法很简单,但是实际上他可以算是结合了Skimming effect 和 Chorus effect, 首先IR系统给高分的document分数会高,然后多个系统给分的document自然也会高。 IR系统的给分标准是不一样的,有的IR系统分值是从0到1,而另一个是0到1000,这时候就需要normalization。 一个Standard normalization 方式是 origin - min / max - min 这样就能得出一个分布在 0 - 1之间的范围 另一个CumbSUM的变种是CumbMNV,也就是将Chorus effect 进一步放大。 它将每一个CumbSUM结果乘以出现那个词的Relevant document数。 现在这两种还是太简单了,可以给每一个IR系统一个weight,这样更符合实际。 这也就是Linear combination,那么每个词的总score就是score*权重的累加 有两种算法常用来计算权重。 CORI algorithm使用DF 和 Inverse Collection Frequency LMS 算法对返回较大result set的系统权重高(简单但是实际上很好用)。
Probability
如果仅通过一个简单的weight 权衡整个返回结果会丢掉信息。 在Probfuse 算法中,决定顺序的是这个文档有多大概率是相关的。而这个概率是通过检验历史数据得出的。
Probfuse 算法(老师干的)
算法分为两个阶段 首先我们要训练IR系统。对于系统返回的result list 切成多个segment,然后用过往数据评定这个segment有多relevant(rel/ result),用这个值作为segment 的 weight。 接下来是评定阶段,在result 的哪个segment就按哪个weight来乘。如果文档出现在多个系统中就累加(Chorus effect)。
Segfuse(老师没干的)
一个明显的改进就是把segment取的不同。在当前文档中1和segment1的末尾视为一个weight,丢掉了skimming 信息。因为前面的部分相对重要,后面的相对不重要,因此可以取前面的区间小,后面的区间大 区间数量为(10 x 2^k-1) -5 k为segment号
Slidefuse (老师干的)
这里考虑的idea是相邻的文档可能有关,有相似性,而segment的切分会导致丢掉这部分相似性。 因此我们可以考虑以附近的rel的概率作为该位置的概率,而不是靠segment 切分这样会更加的平滑。 Fusion 时对于某一个document检测silding window probability,然后把系统结果们加起来。按总分排序。
PageRank 算法
在之前介绍的现代IR流程中,PageRank大概算是Feature extracting部分
Page rank是一个不同于我们之前学到的IR系统的打分方式,因为之前的打分都是使用内容来评价一个document的相关程度。 但是对于某些领域来讲,很难界定内容的重要程度,比如科研论文,比如网页。对于这些内容来说,内容的发布者很有可能比内容本身更为“权威”, 也就是重要。这种情况下就不能单独看内容了。 借鉴于科研系统搜索,google 引入了一个pagerank 经典算法,idea简述就是通过引用链接来分配重要程度,被引多的网站重要程度高。相比于之前的准确性增加了importance这个维度。 简化版PageRank:
- R(u):页面 u 的 PageRank
- Bu:所有指向 u 的 backlinks
- R(v):backlink v 的 PageRank
- Nv:v 的 outlinks 数量 其实就是一个页u可以得到的score等于所有他的backlinks可以给出的,一个页u可以给出的等于它的score/它的所有outlinks(总score平分)。 这个公式的问题就是没有beginning,只有有了score之后才能开始计算score。 解决方式是给每个页数一个初始值,然后通过多次迭代计算来让值变化。一直重复计算到score不怎么变化(收敛)之后运算结束。
在一个有输入无输出的回环路径中会出现score无限上涨的情况。 ![[信息检索4Ragerank例子.png]] 为此我们引入了damping factor d,并将公式更改为
Web IR
爬虫(Web crawling)
在网上收集信息需要用到爬虫,爬虫最简单的流程就是:
Seed URLs
↓
URL Queue
↓
Fetch Page
↓
Extract Links
↓
Add New URLs
↓
Repeat通过一个广度优先搜索来收集信息, URL就是edge,而网页就是vertex. 因为这种方式支持并行搜索因此不会浪费很多时间.
Polite crawling
虽然爬虫很方便,但是粗暴的搜索会给服务器带来伤害,比如overload掉服务器,因此通过一些简单的限制可以降低网站的负担:
- 遵守 robots.txt
- 遵守 Crawl Delay
- 不占用过多带宽
- 标识自己的身份
这些标准都是网站对爬虫的期望,而不是强制要求. 通过在网站根目录设立robots.txt,让爬虫自动读取来告诉爬虫允许的行为. 使用方法:
User-agent: * // 所有爬虫
Disallow: /tmp/ //不允许访问这个地址
Disallow: /cgi-bin/
User-agent: GoogleBot
Disallow: // GoogleBot全部允许noindex 与 nofollow
通过在页面的metadata中的content或者在某一个link的属性中添加noindex or nofollow属性可以告诉bot不要建立索引或者不要follow link
<meta name="robots" content="noindex" />表示:
不要建立索引<a href="..." rel="nofollow">表示:
不要沿着该链接继续爬取web中IR的challenge
- URL Duplication // 两个连接指向一个页面: 比如 www.Limboo/1 和 www.Limboo/第一章 可能是一个界面(这只是个例子), 这会影响到pagerank的结果和造成重复
- Dynamic Pages // 爬虫刚爬完网站就更新了
- CAPTCHAs // 验证码
- Deep Web // 没有被链接连到的网站.
- AJAX 不好被爬取
对抗性IR
在传统内容检索中不会考虑到IR系统, 但是到了网络上就会出现对搜索引擎优化(SEO) 通过一些技巧,作者可以让自己在搜索引擎中的排名增加,而这又分为了两大种方法: White hat(守规矩/白客)/ Black hat(不守规矩/黑客) White:
- 提高内容质量
- 优化标题
- 优化 URL
- 满足用户需求
Black: 手动操作排名,违反了操作引擎规则, 这就属于对抗性IR.
- Metadata 通过向Metadata中手动加入很多很多tag和热门词来扩大命中率.
- Hidden text 基本类似1,但是在后期搜索引擎不依赖于检索metadata后作者将白色文本放入网站.这些文本用户看不见,但是搜索引擎会考虑进去. 增加TF,增加
- Cloaking 给爬虫和用户返回不同的界面
- Sneaky JavaScript 通过<noscript> tag 让爬虫看到另一个界面,用户被JavaScript导引到别的界面,本质3
- Link farm 建立一些网站纯粹转发链接,来提升PageRank级别.
- Comment Spam 在论坛里大量散布链接, 增加backlink值
- Doorway Pages 为不同query建立大量界面,但是最后跳转到同一个网站,也是增加命中率
考试
带计算器,保留三位小数