前言:
暂时这个还只是beta版本,我目前还没有写完整个知识框架,只是一个章节一个章节的写笔记,当我整个弄完之后我会修一下笔记
Introduction
1. 什么是分布式系统?(What is a Distributed System?)
广义上,从弱耦合的互联网到强耦合的多核处理器都属于分布式系统。
1.1 本课程定义
一组“独立计算机(independent computers)”,通过“网络(network)”通信与协调行为,对用户呈现为一个统一的“系统(single coherent system)”。
关键特征与动机
| 特征 | 含义 | 为什么重要 |
|---|---|---|
| 独立计算机 | 每个节点独立运行,可独立失效 | 必须设计成允许“部分失败”,不能像单机那样“一挂全挂” |
| 网络连接 | 无共享内存,通信靠消息 | 延迟、丢包、乱序常见 → 分布式算法复杂性来源 |
| 消息传递 | 使用 send/receive 协调行为 | 所有同步机制都必须基于消息协议实现 |
| 呈现为一个系统 | 对用户隐藏内部复杂性 | 用户看到的应该是一个整体,而不是数百台机器的集合 |
2. 一个分布式系统应当能做到什么?
分布式系统核心目标:
透明(transparent)・开放(open)・可扩展(scalable)
注意:透明(transparency)并不是“看得见”,而是“对用户无感”。 这里的透明性的意思其实是用户使用资源的时候仿佛没有经过分布式系统一样,是无感性。 分布式系统使用中间层隐藏底层网络、位置、复制等细节,使用户感觉就像在使用一个单机系统。
2.1 可用(Availability)
系统必须允许用户或其他系统使用其资源,不因部分节点失败而中断。
2.2 资源抽象化(Resource Abstraction)
资源包括文件、打印机、数据库等。
为什么要抽象?
- 将底层复杂性对用户隐藏,提供统一接口。
- 抽象 = 用统一接口表示资源(类似 OOP 的 interface)
- 提高可管理性、可移植性,并隐藏复杂性
2.3 隐藏具体结构(Transparency)
用户不需要知道:
- 资源的位置
- 资源的复制数量
- 资源在内部的移动/迁移
2.4 动态扩展(Add/Remove Resources at Runtime)
分布式系统的主要使命之一就是扩容。
- 动态添加节点(scale-out)
- 故障节点的动态移除
- 系统不停机维护
用户希望系统永远保持可用(always-on)。
2.5 可扩展性(Scalability)
系统必须能适应:
- 用户数量增长
- 数据量增长
- 请求量增长
- 地理分布扩展
与动态扩展不同:Scalability 的范围更广,关注整体成长性,而不仅是简单增减机器。
缓存和复制是两个提升扩展性的方法
3. 分布式系统实例(Examples)
Internet
- 透明性:使用 IP 形成逻辑网络,使用户无感知到位置差异
- 开放性:资源可自由加入或退出网络
- 扩展性:IPv4 提供约 40 亿地址(尽管理论上不够,但现实世界这玩意够用了几十年)
术语(Before We Continue)
在进入后面章节之前,需要定义一些基础名词。
主机(host)/节点(node)/机器(machine)
分布式系统的基本计算单元。- client:使用资源
- server:提供资源
站点(site)
含有多个主机的物理位置(如数据中心、机房)。资源(resource)
主机上的程序或数据,可由系统共享或访问。任务(task)
一组目标明确的操作,由分布式系统执行。
4. 分布式系统的优缺点
分布式系统从一开始的内含的复杂性就远高于普通的中心化服务器,那为什么要构建一个分布式系统呢?
构建分布式系统的难点:
必须考虑 组件分工、位置分布、通信方式、协作模式、负载管理、容错 …
我们要看看常见的领域来分析优缺点:
4.1 资源分享(Resource Sharing)
节点可以使用其他节点的资源(如 A 用 B 的打印机)。
优点
- 能获取原本没有的资源
- 能共享闲置资源,提高系统利用率
缺点
- 资源管理与冲突处理变复杂
- 例如:A 与 C 同时想使用 B 的打印机;或 B 的打印机已宕机但 A 尚不知情
4.2 并发处理(Concurrency)
多个主机可同时处理多个任务。部分任务可拆分后并行加速。
优点
- 提升吞吐量
- 并行化降低任务完成时间
缺点
- 容易出现负载不均(某节点过载)
- 任务调度、通信开销可能抵消并行收益
- 正确性问题(如并行写文件时的冲突)
4.3 全局时间(Global Time)
许多分布式任务需要共有的时间概念,比如在金融系统里的订单顺序,或者两个机器人决定同步提高速度,提升效率的时候需要同步时间。
问题
- 物理限制使真正的全局一致时钟不存在
- 现有的同步算法(NTP 等)都有一定程度上的误差。
- 因此事件排序不能依赖物理时间 → 必须使用逻辑时间(Lamport Clock)来决定顺序。
4.4 可靠性(Reliability)
可靠性:在部分系统组件失效时仍能继续提供服务。
- 对系统而言:节点挂了不应导致整体宕机
- 对用户而言:某个资源不可用时应能找到替代资源
理论上,分布式系统因冗余设计更可靠;但现实中由于复杂性增加,并不总是更稳定。
4.5 拓展性(Scalability)
理论上:“遇事不决加机器”。
但实际扩容会带来许多问题。
扩容的现实问题
新机器是否有需要的资源?
如你需要打印机,但新增节点没有扩容对网络的影响?
若系统缺乏规划,大量节点可能让网络压垮
(例如最简单的通信方式就是每节点占用一个端口,但是当机器数大于端口数的时候就炸了)扩容会降低整体可靠性?
节点越多 → 故障概率越高
更多副本 → 更多同步成本 → 更多复杂性
5. 分布式系统挑战
5.1 异质性(Heterogeneity)
系统必须运行在多种硬件、操作系统、语言、网络环境中。
这是构建分布式系统最根本的困难之一。
5.2 开放性(Openness)
开放系统允许:
- 功能扩展
- 集成新的资源/服务
- 使用公开接口(API/协议)
- 使用统一通信方式
现实中由于商业、兼容性、安全性等因素,开放性常常只能部分实现。
5.3 安全性(Security)
安全性关注保护敏感数据:
- 通信加密(encryption)
- 身份认证(proof of identity)
外部攻击包括:
- 中间人攻击
- 数据篡改
- 拒绝服务攻击(DoS)
5.4 崩溃处理(Failure Handling)
节点会失效,因此系统必须支持:
- 错误检测(detect)
- 错误隐藏(mask)
- 容忍(tolerate)
- 恢复(recover)
- 冗余(redundancy)
容错能力是分布式系统可靠性的基础。
5.5 透明性(Transparency)
透明性:用户不需要知道系统是分布式的。
系统应实现:
- 资源移动透明
- 负载重新配置透明
- 结构扩展透明
用户操作不应因内部变化而改变。
6. 模型(Models)
6.1 系统模型(System Models)
描述分布式系统面临的外部困难:
- 使用模式多样(workload 多变)
- 系统环境多样(异构硬件/网络)
- 内部问题(时钟不同步、冲突更新、硬件故障)
- 外部威胁(DoS、攻击等)
System Model = 分布式系统的外部制约(external constraints)。
6.2 结构模型(Architectural Models)
系统设计蓝图,包括:
- 功能模型(各类型节点的职责)
- 组件如何分布在网络中(部署方式)
- 组件之间如何通信(交互方式)
结构模型决定系统的整体组织方式。
6.3 分布式系统层级
自底向上:
- 平台(Platform):硬件 + 操作系统
- 中间件(Middleware):提供统一接口,隐藏差异
- 应用服务(Applications):实际的分布式程序
7. 中间件(Middleware)
中间件是一个介于应用与底层之间的软件层,为开发者提供统一抽象,避免直接处理网络、硬件、通信协议等复杂性。
7.1 中间件的功能
- Remote Method Invocation(RMI)
- Group communication
- Event Notification(发布/订阅)
- 共享数据的分区/放置/查询
- 数据复制与一致性维护
- 实时多媒体传输(视频、语音等)
例子:
- Sun RPC
- CORBA
- Java RMI
- Web Services(SOAP/REST)
- Microsoft DCOM
7.2 中间件的缺陷
中间件通常假设通信是原子的(atomic)
现实中通信常包含:部分成功、部分失败、中断、断点恢复需要应用语义的功能无法靠中间件实现
如 FTP 断点续传必须在应用层记录传输偏移量端到端原则(End-to-End Argument)
某些正确性检查只能在应用端点实现,而非中间件或网络层
→ 可能导致部分功能重复,但这是必要的设计
基本架构
设计需求
性能
对于性能来说有三个影响要素:
- 响应性(Responsiveness)
- 吞吐量(Throughput)
- 负载平衡(Balancing Computational Loads) 用户与系统交互的时候期望快速而连续的响应(用户界面的快速更新)。但是服务器经常会访问一些共享的资源,因此服务器当前的负载,网络延迟,中间层消耗和代码运行的时间都会影响响应性。通过
- 减少应用的软件层级
- 减少客户端和服务器之间传输数据的量。
来提升性能。
吞吐量基本就是服务器处理任务的能力。跟响应性的概念差不多,但是会受到客户端和服务器两端的影响。在应用层面,软件各个层级的瓶颈也会影响整体表现。 负载均衡的意思就是使用所有可用的计算资源,在不争抢相同资源的情况下运行多任务。比如JS用客户端分散运行,或者部署多个服务器然后分散负载。
软件层级是指构成一个分布式系统的层级,举个例子: 前端->web服务器->中间层->数据库。 要是根据你的应用逻辑,你的数据处理服务器(后端)还有不同步骤的话,软件也就分了层。
QoS(服务质量)
基本由四要素构成:
- 可靠性(Reliability)
- 安全性(Security)
- 性能(Performance)
- 适应性(Adaptability)(新增) 适应性指的是能适应资源的变化,系统设置的调整,基本上就是弹性的意思。 影响性能的还有时间敏感性:数据在进程之间的传递必须在固定时间内完成。多见于视频网站或者游戏的需求。
核心模型
客户端-服务器模型(client-server)
客户端通过独立的进程向服务器请求由服务器管理的资源 服务器在请求资源的时候也是一个客户端。
p2p模型(peer-to-peer)
节点之间互相连接,互相分享资源。节点之间没有server和client这种级别的差距
变种模型
多服务器模型
一个服务根据逻辑拆分到多个服务器上,有多个服务器整体提供一个服务。
数据库+数据处理服务器+前端界面服务器
中间服务器(代理+缓存)
中间服务器可以用来应对上面的性能和QoS需求。 缓存服务首先检查有无可用copy,无的话则向后请求最新,然后存下。它可以显著减少客户端的响应时间(响应性) 缓存服务可以是本地的,也可以是在一个共享的代理服务器上。 代理服务器是一个架设在clent和server之间的中间层,作转发,记录和缓存
移动代码(mobile code)
对于某些不依赖于平台的代码来说,这些代码可以先发送到主机上,然后再运行。 优点是方便,而且可以用客户端自己的性能不占服务器.
缺点是安全性问题,代码发送到本地意味着很容易被操作。
网络电脑/瘦客户端
跟传统主机不同,网络电脑本地什么都没有,操作系统和应用本体都通过网络下载。主机只拥有最小程度的存储,且大部分储存都是缓存,用来加速访问。应用是本地跑的,但是文件什么的都在远程。优点是成本低,好维护并且移动用户的成本低。
瘦客户端跟网络电脑的区别是连应用都是远程跑的。 缺点是断网或者网络波动都有可能造成数据的丢失,如果图像比较复杂可能会影响性能。(X11居然是按client-server模式的瘦客户端设计的)
缓存可以减少响应时间,复制可以减少网络开销,平衡负载。
分布式并发问题
一个中心化系统有单独的内存和时钟,因此没有并发问题,但是在分布式系统中确定事件发生时间就很麻烦。因此我们只要使用一个普适的时钟就好了!
物理时钟
如今的“准确”时间是通过天文测定的,也就是所谓的太阳日(solar day),但是地球是在慢慢减速的,地核运动,地球到太阳的远近也会导致波动误差。通过平均太阳日可以修正一点误差得到当今的24小时。
当今的精确时间使用的是铯原子钟,精度极高。TAI(国际原子时)直接由原子时钟计算,UTC(协调世界时)是TAI加入闰秒。通过广播或者卫星可以获得UTC的时间。
对于每个电脑来说,它们主板上都有一个独立供电的内置硬件时钟,用于初始化操作系统的时间。但是实际上不能保证两个机器的时间变化速度是完全一致的,因为晶振频率是是有偏差的导致了时钟偏移(clock skew)。
制造商可以给出每秒的最大偏移率
时钟同步算法
中心化算法(由一个主机负责系统的全局时间)
Cristian’s 算法:
一个主机负责授时,其它客户端每
- 小问题: 延迟
解决方法: 客户端记录自己收发时间为, , 然后 作为延迟的估计,加在 就行
延迟时间是客户端记录的,跟它的时钟有关,不过只要时钟漂移不是很大就可以忽略。
- 大问题: 客户端的时间比授时主机快
客户端的时间变慢,主动降低每秒tick数等主机追上来。(而不是直接倒流时间)
Berkeley 算法:
这是一个局域网内同步时间的算法。一个电脑为master,其它电脑为slave。主机定期获取所有slave的时间,计算平均值作为系统(自己)的时间。然后告诉给每台机器各自该怎么调整时间。核心思想是多个client时间的平均值会比单个client的时间要精确。
分布式算法
平均算法/NTP: 所有机器定期播报自己的时间,机器的时间设定为受到的时间的平均值。
逻辑时钟
这是另一种处理分布式同步问题的思路,也就是使用一个所谓的相对时间(relative time). 这个相对时间处理的不再是精确的时间,而是事件的顺序:
- 时间发生顺序
- 因果顺序(内含了发生顺序)
Lamport 逻辑时钟
通过观察,我们可以发现两个基本原理:
- 如果两个进程没有交互的关系,那么它们的时钟不需要同步,因为不影响他们的执行。
- 对于进程来说,有没有一个共享的时间概念不重要,重要的是能不能确定一个两边都认可的事件顺序。
因此为了表示进程之间的时间关系,Lamport 引入了"“happens-before”关系(用->表示) happens-before关系的特性:
1. 如果在同一个进程内A早于B,那么A->B
2. 如果A向B发送消息,B收到消息,那么A->B
3. 这个关系有传递性,A->B, B->C, 那么A->C
4. 如果A和B之间没有->的关系,那么他们同时(concurrent)发生那么现在根据这个定义就有一个问题了: 如果A->B,但是A的本地时间
局限性: 如果 A->B, 可以推出
P0: A(8) ------>
P1: B(9) ------>
两线无交叉,单纯就是A时间戳比B小向量时间(Vector Time)
为了解决这个因果问题,引入了一个多维向量(其实就是一个进程数长度的数组Array[N]),这个向量储存了主机视角下全局发生的事件(快照)。 对于 N 个进程,每个进程维护一个长度为 N 的向量 V:
- V[i] 表示“我所知道的,进程 i 已经发生了多少事件”
向量时间算法步骤:
- 所有进程初始化为0
- 每次发生事件,进程 i 的向量 V[i] + 1
- 发送消息的时候,把向量 V 发给接收方
- 接收方收到消息,首先把自己的V[self]+1 然后对每个分量 i:V[i] = max(V[i], V_msg[i])。
这样为什么解决了因果关系呢?因为如果两个event,A->B,那么A的V就发给过B,B的所有的V[i] >= A的V[i](B的已知历史由A前进了一些)如果没有因果关系,那么就会存在有某一个维度的V[i] < A的V[i](这个地方挺好想的但是我不太会解释,按照视角这个思路想一下就行,略)。
全局状态
在很多时候,我们不止需要某一个process的状态,而是要储存一个全局的状态。
最简单的做法是给每一个进程都发信息,收到信息的进程把自己的状态写到硬盘里。(慢而且不一定连续)
Cut:时间的前沿,在cut之前的所有时间在这个cut里,之后发生的在cut外。
一个连续的cut指的是cut内的所有事件:如果A->B, B 在cut内那么A在cut内。
选取到一个连续的cut作为全局状态就是我们的目的。
快照算法(Snapshot Algorithm)
这个算法要求很多前置条件:
- 所有的通道和进程都不会失效,每一个发出的信息都是会被收到的。
- 通道双向且遵循FIFO原则。
- 强连通图
- 任何一个节点在任何时间都可能开始全局快照
- 在收发快照信息的时候,其它信息传递不会停下。
有一个博客的这个算法讲的很好,我建议看她的博客.
算法步骤: 每个节点维护一组入站通道状态,比如节点1有Array[C(2,1),C(3,1),C(4,1)....] 这个算法的核心就是两条规则 Marker发送规则
1.记录自己的状态
2.对于自己的每一个出站通道,发送一个MarkerMarker接收规则
第一次通过通道C接收到Marker:
记录自己的state
通道C设置为empty
向所有的出站通道发送Marker
开始记录其它所有入站通道的信息
其它:
C的进展通道记录保存为之前记录的信息最终每个节点都会有自己的状态和一个通道里收到的信息的状态。所有节点的状态加在一起就是全局的快照。
资源互斥
对于一个分布式系统来说,互斥是保护共享资源的一种手段。非分布式系统中可以使用类似信号量(Semaphores)之类的技术实施临界区(Critical region)来实现互斥。在分布式系统中也采用了类似的技术。
中心化算法
使用一个coordinator管理所有的资源,如果想进临界区就发请求给coordinator,可用回OK,不可用等着。用完资源通知coordinator。 优点:
- 简单
- 能用
- 公平
- 不会饿死 缺点:
- 单点故障,容易有瓶颈。
分布式算法(Ricart-Agrawala)
申请进入临界区就广播[申请者ID,资源ID,时间戳],所有进程回OK就进。如果有进程在临界区就会回复NO,如果有进程在等着这个资源就根据时间戳(时间戳小获胜)来决定发NO还是YES。 优点:
- 不会单点故障
- 能用
缺点: - 变多点故障了,任意故障都会造成阻塞
- 消息多
- 所有节点要维护所有节点列表 ppt老师总结是烂完了。
Token-Ring算法
所有进程逻辑上组成一个环,持有token的进程可以进临界区,用完token给下一个 优点:简单,公平,不会饿死 缺点:
- token丢了
- 进程挂了
- 环不好维护
- 想再次进入临界区得等一圈
总结
这仨都各种问题,只有在崩溃少的系统里勉强能用。
选举算法
分布式系统中有些情景需要选出一个特殊职能的节点(比如leader什么的),这时候我们就需要一个算法来进行这个步骤。
在开始介绍算法之前,我们应该先确定这个选举算法的一些性质:
- 所有的节点都应该能参与
- 选出的那一个结果所有节点都应该同意。
- leader在被选出之时就开始形式leader的职能直到fail或者行使了什么退休机制。
选举算法的效率是通过计算算法占用的带宽和时间来确定的。
环形算法(Ring Algorithm)
得名环形算法的原因是因为,所有的process被视作在一个逻辑环里。
- 所有的进程从左进程收到消息,并将消息向右传。
- 所有进程在本地持有一个活跃进程表
算法流程:(ppt)
某个进程检测到leader挂掉之后开始选举流程:
- 构建一个election消息,放入自己ID
- 每经过一个进程就加入自己的ID(进程失效就往下跳,直到找到一个活跃的)
- 发起者发现自己的ID在election消息里就说明走完了
- 将ID最大者定为leader,发布一条coordinator消息
- coordinator消息环形走一圈通知所有人。
算法流程:(经典版)
某个进程检测到leader挂掉之后开始选举流程:
- 构建一个election消息,放入自己ID
- 每经过一个进程就比较里面ID的大小,如果比自己小就替换,大就继续传,一样就就说明自己就是那个最大的
- 将自己(最大者)定为leader,发布一条coordinator消息
- coordinator消息环形走一圈通知所有人。
算法分析
我认为老师的算法复杂度分析这里有问题,按照老师的ppt的版本这里好坏都是2N,但是ppt里给出的是3N-1,我就解释一下: 经典版的最坏情况是最大的节点在最后一个节点,也就是发起节点的左节点,那么一共就要N-1个election消息才能到最大节点,然后这个最大节点需要消息再从所有的节点过一遍(N)才能第二次收到这个election消息并发现自己是最大节点,之后要发一个coordinator消息环形走一遍通知所有人(N),也就是3N-1
霸凌算法(bully algorithm)
顾名思义,这个算法的核心就是ID大的可以欺负ID小的。
假设
- 所有的进程互相都知道ID和地址
- 通信可靠
算法流程
- 节点P 发现原 leader 挂了(或刚恢复):
- 如果自己 ID 最大 → 直接发 COORDINATOR 给所有人,当 leader。
- 否则:给 所有 ID 比自己大的进程发 ELECTION。 
- 如果没有收到任何 ANSWER:
- 说明所有比自己 ID 大的都挂了 → 自己发 COORDINATOR,当 leader。 
- 如果收到某个更大 ID 的 ANSWER:
- 自己就老老实实等,不再发选举消息,等别人发 COORDINATOR。 
- 如果 P 收到一个来自 ID 更小的进程的 ELECTION:
- 回一个 ANSWER(告诉他“我比你大,我活着”)
- 然后自己也按第 1 步发起一轮新的选举(“抢权”) 
- 收到 COORDINATOR 消息 → 认这个 sender 为新 leader,更新本地记录。 
算法分析
最坏带宽:约 N^2 - 1 条消息。 
- 最坏情况:最小 ID 的进程发现故障,它会给所有更大的发 ELECTION,然后一串人层层再发选举,消息N^2 - 1。
- 最坏 turnaround:大约 N−1 轮“波次”。  最好带宽:N-2 条消息。
- 最好情况:第二大 ID 发现 leader 挂了,直接发 COORDINATOR: 带宽 ~ N−2
- turnaround time只要 1(所有并行发)。
分布式文件系统
分布式系统的核心目标之一就是实现资源的共享。文件可以通过“数据库”,“共享内存”等方式存储,但同时也需要一个更高层的文件系统来管理。
分布式文件系统让远程文件可以像本地文件一样访问
分布式文件系统功能
文件系统一般负责文件的组织(organization),存储(storage),检索(retrieval),命名(naming),共享(sharing)和保护(protection)。
模块划分(逻辑上):
- 文件夹模块(名字 → 文件 ID)
- 文件模块(文件 ID → 实际文件)
- 访问控制模块(权限)
- 文件访问模块(读写)
- 磁盘/设备模块(磁盘块、I/O)
一个分布式系统的组件:
- 文件服务器(File Servers): 提供储存,处理客户端请求
- 客户端(Clients): 发送请求,给用户提供统一接口
- 文件服务接口(File Services) 定义基本操作(增删改查)
DFS的例子有 Novell 网络组件和Windows文件共享。
DFS的关键问题
在这个文件系统中,主要要处理的就是6个关键问题
1. 命名(Naming)和透明性(transpaency)
在实际的硬件存储中,文件是由文件ID和物理地址来表示的,命名其实是由名称再加上逻辑上的分组构成的。听起来有点抽象,但是在正常的目录文件系统中指的就是文件名和他的地址,比如/home/user/file.txt。这种命名的手段让我们可以把逻辑上操作的文件和实际物理上的那个文件分开考虑。这为DFS提供了位置透明性和位置独立性。
位置透明性: 文件的物理储存位置不显示在文件名上。(有助于文件分享)
位置无关性:在文件的物理存储位置改变时,我们不需要去动文件名。(更好的文件抽象,将逻辑上的文件和硬件层分开)
访问透明(access transparency): 一个小问题是当今的文件系统大部分还都是单机系统,因此在我们想要透明的(transparently)访问文件时,我们要先连接到资源,这个行为叫做挂载(mounting)。当你挂载之后,你就可以像是操控本地文件一样管理远程文件了,因为它们使用了一个接口。
全局命名:我怎么能知道/home/john/thesis.tex和/mnt/john/thesis.tex是同一个文件呢?使用全局命名。
这样所有的机器看到的都是同一棵目录树。(理想情况下DFS下组合出的文件系统应该跟本地系统相同,但是实际上因为有设备树和某些机器特有文件的原因不能实现)
2. 远程文件访问
下载/上传模型
核心思想: 把需要访问的文件下载到本地,然后访问,用完后上传回去。
因此这个模型只提供了两种基本的文件操作:读和写。读操作把文件从服务器传输给客户端,写操作把文件从客户端上传到服务器。 优点:简单 缺点:客户端首先要有足够存储空间,而且大多时候都不必要传输整个文件的。
远程访问模型
核心思想:远程控制文件系统,文件系统操作服务器上的文件。
因此这个文件支持所有的文件操作。
优点:客户端不需要很大空间,在只需要一小部分文件碎片的时候不拉取整个文件。
缺点:会多次访问同一个文件(缓存能有所帮助)↓
将最近访问的磁盘块加入缓存,这样重复访问可以本地处理了。
缓存(Caching)
缓存位置:硬盘VS内存
硬盘?:可靠,持久,重启还在。 慢
内存?:快,无磁盘主机可用,内存越大越快。服务器端端数据总是在内存里,如果客户端也放内存就可以共用逻辑了。 不可靠
缓存更新逻辑:立刻写入(writes immediately propagated to server)VS延迟写/关闭写入(updates propagated on close / later) 立即?:可靠,速度慢
延迟?:写入快,效率高,统一写入减少了无效操作(写了又删)。可靠性不好,本地崩溃时没写入的东西会丢。
缓存一致性问题:客户端VS服务器端
客户端?: 客户端检查本地缓存是不是最新的,不是就从服务器端申请。服务端再检查客户端的文件是不是跟最新一致。
服务器端?: 服务器记录每一个客户端缓存的文件。当服务器端发现有缓存文件不一致时就做出反应(比如推送最新文件)
优点?:
- 加速远程文件的访问,让它们的访问体验跟本地类似。
- 缓存在读多写少的应用中表现优越。(写多时在解决一致性上的开销会变大)
- 减少整体网络开销。(传完整大文件>零碎小文件)
- 本地有硬盘或大内存时缓存有效。(无盘和小内存主机不应该使用缓存)
3. 有状态(stateful)VS无状态(stateless)
有状态文件系统(类似TCP)
服务器与客户端保持一个连接,服务端记住客户端的操作和当前状态,然后更新和保留这个状态直到声明这个操作结束。
优点: 高性能。有状态所以服务端知道操作类型,如果是顺序读写可以预读(read adead)
无状态文件系统(类似UDP)
每一次请求服务器都当是一个自包含(self-contained)的,请求要指出要访问的文件名和文件内数据的位置。 无状态请求可以不用维护和终止连接,每次发的都是完整的一个操作而已。
Versus!
- 崩溃恢复: 有状态每次崩溃会丢掉整个操作,崩溃恢复很复杂。无状态的崩溃回复几乎不会被察觉,重新请求一次操作就行。 无状态很慢,一个稳定的无状态服务代表着更长的请求信息和更慢的请求处理。
- 有些情况要求有状态,比如之前的缓存由服务端管理就需要服务端保有每个客户端的信息。
4. 文件复制
一个文件复制多份放在不同的主机上,命名系统记住文件的每一个副本,但是向用户隐藏。在逻辑上只存在一个文件。
WHY?
复制提升性能。用户访问文件的时候可以访问据他最近的服务器上的文件副本。提高可用性,一个服务器崩了不会丢失文件。 复制又带来了一堆问题。
问题(这玩意目前老师好像也没给解决办法,就纯摆着)
更新问题: 一个文件的更新要同步到所有文件上(慢,而且带宽开销大) 需求复制: 访问非本地文件导致本地又存储了一个缓存,这个缓存也就是那个文件的又一个副本,我们怎么处理这个副本? 并发问题: 两个副本被同时更新,存那个?
5. 安全
安全性是DFS的关键,它代表着访问控制和用户授权。 在DFS中,每一个操作之前都需要验证权限。这里有两种方式
名称解析(类似cookie的token)
服务器验证名字,如果符合权限就返回一个capability凭证,包含有文件id,允许操作,加密签名。客户端凭借这个凭证可以操作文件。在每一次RPC(remote procedure call远程操作请求)时会检查这个凭证。
RPC检查
对于每一个PRC都放上客户端自己的加密签名,然后每次服务端都验证。
平面文件系统(Flat FIlesystem)
我们现在来考虑一下怎么设计一个DFS?
在平面文件系统中不存在目录结构,所有的文件都是通过一个独特的ID来标识的。这样实现了名称和文件位置的脱钩。 系统的文件系统由三个服务构成:
- 目录服务(Directory Services):目录文件负责将目录加文件名映射成UFID(Naming操作)
- 平面文件服务(Flat File Service): 平面文件服务通过UFID获取文件。
- 客户端的文件模块(Client Module): 提供接口来调用远程服务,隐藏服务端的实现细节。
文件组(File Group)是一组位于同一个服务器文件的集合,是打了包的一批文件,方便管理 平面文件系统是一个模型。而SUN NFS是一个这个模型现实中的实现。
SUN NFS
NFS是Sun公司开发的一个网络文件系统,它基于TCP/IP协议,是Sun公司提供的一个开源文件系统。 NFS引入了UNIX下的虚拟文件系统,它可以接入UNIX作为客户端。
剩下的都是工程性的,弄了个大概的表,想看细的就看PPT吧。
| 项目 | FFS(Flat File System) | Sun NFS |
|---|---|---|
| 目标(Objective) | 参考架构 | 简单且可靠 |
| 安全性(Security) | 目录服务 / RPC | 基于 Sun RPC |
| 加密 | Kerberos 集成 | |
| 命名(Naming) | 位置透明性 | 位置透明性 |
| 文件访问(File Access) | 远程访问模型 + 缓存 | 远程访问模型 + 缓存 |
| 缓存更新策略(Cache-Update Policy) | 直接写入 | 周期性刷新(磁盘同步) |
| 不适用(N/A) | 写直达 / 提交时写回 | |
| 一致性(Consistency) | 不适用(N/A) | 基于时间戳 |
| 服务类型(Service Type) | 无状态(Stateless) | 无状态(Stateless) |
| 复制(Replication) | 不适用(N/A) | 不适用(N/A) |
AFS(Andrew文件系统)
这个文件系统的设计目标就是支持5000人并发的文件共享。特点是整文件传输至客户端和整文件本地缓存。如果发生文件变化就由服务器通知客户端更新文件。 问题:本地要一个大缓存。对于数据库这种多个用户和访问和更新数据的应用不管用
实现: 客户端(Venus):整文件缓存,缓存管理,解析路径成id,判断缓存有效性,close时写回数据库 服务器(Vice):提供平面文件服务,管理磁盘文件,组织文件,给客户端发送缓存有效证明(callback promise)
| 项目 | FFS(Flat File System) | AFS(Andrew File System) |
|---|---|---|
| 目标(Objective) | 参考架构 | 可扩展且安全 |
| 安全性(Security) | 目录服务 / RPC | 基于 RPC |
| 加密 | 私钥算法 | |
| 命名(Naming) | 位置透明性 | 位置无关性 |
| 文件访问(File Access) | 远程访问模型 + 缓存 | 上传 / 下载模型 + 缓存 |
| 缓存更新策略(Cache-Update Policy) | 直接写入 | 回调承诺(callback) |
| 不适用(N/A) | 关闭时写回(Write-on-close) | |
| 一致性(Consistency) | 不适用(N/A) | 基于时间戳 |
| 服务类型(Service Type) | 无状态(Stateless) | 有状态(Stateful) |
| 复制(Replication) | 不适用(N/A) | 只读复制(Read-only) |
P2P文件系统
AFS FFS这种强服务器加缓存的文件系统在不断扩大的系统规模下也会遇到瓶颈。这时候我们就要引入P2P这种彻底没有中心点的文件系统,消融掉服务器的概念。P2P是一个为超大规模的文件模型构筑的分布式系统。
P2P 系统是一组对等节点,每个节点有相同的职责,每个节点既是客户端,也是服务器,系统不依赖(或极少依赖)中心节点。 P2P在储存很大的不可变数据时很高效。
关键特性:
- 每个用户贡献系统的资源。
- 每个节点的操作不需要一个中心节点管理
- 节点可以为用户和供应者提供基本的隐私保护
关键问题: 资源是存放在哪里的?(寻找资源): 对于一个有中心系统的文件系统来说(AFS等),文件是由文件服务器提供的,查找不是一个问题。但是对于一个P2P系统来说,找寻资源就是一个问题,我们甚至不知道这个节点是否存在。
这现在还是一个开放式问题
P2P系统种类
中心化系统:有一个中心化服务器负责协调和管理节点之间的通讯。 完全与中心化: 节点的发现和通讯是完全节点间的。 混合: 节点连接服务器来发现其它节点,但是通讯是节点间的。
P2P中间件
对于P2P系统的流行,研究者开发了一个通用的中间件系统。
- 节点在这个系统里是一个peer
- 有一些节点是基建节点,用来优化网络的。
- peer节点连接到这些基建节点,通过这些节点寻址和查找。
- 自组织:所有的节点的维护都是通过节点间的算法实现的,不存在人工干预或者中心节点统筹。
有两个用到的技术(或者概念):
路由覆盖(Routing Overlay):P2P自己维护的逻辑网络,建立在物理网络之上,用来更好的(动态,可拓展,更灵活的)管理信息的传递。
- 节点通过向算法提供资源的GUID(全局文件ID)来获取资源
- 为所有新资源提供GUID(通常使用hash生成)
- 向全局播报新资源
- 移除不可用资源
- 管理节点的增减
路由:寻找网络中信息或者数据传输的最好路径的过程
路由过程受到: 目的地(Destination),带宽(Bandwidth),网络拓扑(Network Topology),路由表(Routing Table),负载均衡(Load Balancing),网络堵塞程度(Network Congestion)的影响
覆盖:一个在物理网络上建立的虚拟网络
DHT:分布式哈希表
- 找到资源的地址
- 储存地址
- 提供get方法
这个表是一个分布在很多个节点上的大哈希表,GUID 为 X 的资源,存储在 GUID 数值上“最接近 X 的节点”上(以及若干个最近的节点作为副本)。GUID是环形结构的,也就是0->2^128-1->0,这样保证永远有最近的定义。
特性: - 去中心化,节点累计行程系统,没有中心节点协调
- 可拓展性,节点多依然高效
- 容错性, 在节点加入离开和失效的时候系统保持可用
Versus!
路由覆盖vsIP路由
拓展性
IP路由:地址有限:2^32, 层级结构导致部分地址不可用 路由覆盖: 基于2^128的地址空间,扁平结构让几乎所有地址可用
负载均衡(Load balancing)
IP路由:流量由网络拓扑结构和与之相关的流量特征决定 路由覆盖: 位置可以是随机的,因此流量特征不一定由网络拓扑决定
网络动态性(Network Dynamics)
IP路由: 路由表更新是异步的,基本在一小时以上。
路由覆盖:路由表可用同步或者异步的更新,延迟基本在秒级。
容错(Fault Tolerant)
IP路由: 容错由管理员人工配置,n重容错成本高 路由覆盖: 路由和对象可以n重复制,保证了n重容错
目标识别
IP路由: 一个IP地址分给一个节点 路由覆盖: 信息可以被路由到目标节点的最近的备份上
安全性和匿名性
IP路由:只有完全信任所有节点的情况下才能实现安全性,无法实现地址拥有者的匿名。
路由覆盖: 在有限信任的环境正可以实现匿名。
P2P中间件总结
P2P 中间件平台具备以下能力:
- 使用 GUID(全局唯一标识) 来命名对象
- 对象位置通过 映射机制(如 DHT) 决定
- 使用 Routing Overlay 进行消息投递
- 提供:
- 完整性保证(安全哈希)
- 可用性保证(对象复制 + 容错路由)
P2P的优点(总结)
- 可以淘汰主机的过时资源
- 支持极大数量客户端和主机的同时保证极佳的负载均衡
- 中间件的自组织特性保证了维护成本与主机和客户端数量无关。
案例研究:Pastry
核心:节点为Node,拥有唯一NodeID,使用前缀匹配进行路由。 每个节点存储距离自己最近的一系列节点位置成为叶节点,一半大一半小。 每个节点有一个路由表(Routing table),第n行保存与自己ID有n位相同的Node的位置,当传递消息时向离目标最近的节点发送过去。
组通信
组通信是一个多播(multicast)通信机制:一次发送,将一个消息(几乎同时)送达一组进程 组通信的实现需要考虑是静态组还是动态组,是多播还是单播(这里老师没有讲) 优点:
- 高效: 一个消息给n个进程比n个消息给n个进程要高效。
- 保证接收: 如果使用的是单播,那么部分失效就会导致有的进程收到了有的没有,以及收到消息的顺序不一致。
多播的范围
从弱到强,多播行为分为了三个层次:
- 不可靠多播: 没有对于收到和顺序的保障,一个消息就单纯的发一次
- 可靠多播: 尽量让所有的组成员收到消息
- 原子级多播(Atomic Multicast): 所有的成员要么全部收到消息,要么全部不收。
最基本的多播: IP多播(网络层)
- IP 多播使用 224.0.0.0–239.255.255.255 地址段。
- 基于 UDP(不保证交付)。
- 支持动态入组/退组,通过多播路由器转发;TTL 可限制传播范围。
- 实际多用于集群/机房内。
多播系统的构建
前提假设:
- 进程间存在可靠一对一信道。
- 进程可加入多个多播组
- 每个组有唯一全局ID
基本操作:
multicast(g,m) 向g组发布消息m
deliver(m)向应用交付消息m //这里用deliver的原因是因为接收(receive)的第一时间并不一定会交付给应用层进行处理。
sender(m)返回消息的发出者
group(m)返回目标组。基本多播(basic multicast)
- 静态组、保证送达。
- 实现方式:对组内每个进程做一次可靠单播(TCP什么的)。
- 多线程可以保证几乎同时发送单播信息 问题:
ACK-implosion(确认风暴):规模变大时 ACK 同时返回导致拥塞与重传,这样就会导致丢掉ACK消息,进而导致更多的消息重传和ACK确认。
可靠多播(reliable multicast)
我们可以利用IP多播构建一个更可靠的多播系统 在基本多播之上,增加三项保证:
- 交付完整性(Integrity):每条消息m被正确的进程p交付至多一次;且m来自合法发送者、p属于目标组。
- 有效性(Validity):正确进程发送的消息最终会被自己交付。
- 一致性(Agreement):若某正确进程交付了 m,则所有正确成员最终都会交付 m。
在这些的基础上,又引入了两个新的操作:
R-multicast(g,m)
R-delivery(m)其实就是可靠版的原操作,没啥区别
可靠多播的实现:
可靠多播由三个组件组合:
- IP多播传输消息
- piggyback ACK将确认消息掺入后续多播消息里
- NAK在检测到缺消息的时候主动请求重传。
每个进程要维护:
- Sp 自己所属的组g的消息序号p(sequence number),它记录了自己给组g发送的消息数
- Rq 每一个同组进程发的最近的消息序号(我目前为止从q连续交付到哪个序号)
收发规则:
发送端:
当进程p多播的时候,消息里附加:
1. Sp
2. 一个ACK集合,类似<q,Rq>的集合表明自己从q连续收到消息到Rq
发送之后Sp + 1
接收端:
当收到消来自p序号为S的消息,只有S是Rp+1的时候才能deliver,并且给自己的Rp + 1
大于Rp+1说明中间丢消息了,先扔进缓存的队列(hold-back queue)等待补齐之后再deliver
在接收到消息的同时检查消息里带的ACK,如果发现里面捎带的ACK集合中的某一个Rq大于你的Rq,说明有人已经收到更后面的消息了,但你还没有收到。这说明你漏掉消息了。
发送NAK请求重传。组成员服务(Group Membership Service,GMS)
组成员服务为动态管理组员和多播提供支持 主要功能:
- 成员变更接口(建组/销组、入组/退组)
- 失败检测(崩溃/共同失败;标记 suspected/unsuspected)
- 成员变更通知(通知加入/排除)
- 组地址展开(将组标识映射到成员地址集合)
IP Multicast 只实现了部分 GMS(入/退组、地址展开),不提供失败监控与成员变更通知。
组视图(Group Views)
- 组视图:当前组成员的有序列表(按加入顺序等)。
- 成员变化 → 生成新视图并交付给所有成员。
- 每个成员维护本地视图,确保对“当前成员集合”的一致认知
组视图的更新类似于多播信息的delivery,即:
- 当成员变化时GMS传递视图
- 视图都带有一个ID用来表示身份,
- 所有成员跟踪自己的下一个视图
- 如果到达顺序不对就放到缓存队列里。 要求:
- Order:所有进程对视图的交付顺序一致
- Integrity:交付视图 v(g) 的进程 p 必须属于 v(g)
- Non-triviality:可达的加入者最终会出现在后续视图中
通过加入组视图可以强化组通信的交付(视图同步组通信(View-Synchronous Group Communication)): 新视图到达在系统中画一条“分界线”,消息要么在旧视图内被所有人一致交付,要么在新视图之后处理。 规则要点:若发送者在消息被交付的视图中已不在组内,该消息不得交付。
提供的新特性:
- Agreement:所有正确进程交付相同的视图序列与相同的消息集合
- Integrity / Validity:消息不重复、合法、自己发送必达
- 失败显式化:若消息无法交付,会通过新视图排除失败成员
总结(Summary)
- 组通信关注向进程组(静态/动态组)发送消息。 技术路径: 基本多播(信息的可靠交付,实现单播) → 可靠多播(完整性,有效性,一致性)
- 多播实现关键机制:ACK 捎带、hold-back 队列。
- 组成员服务为动态组实现提供功能
- 组视图和视图交付构成了视图同步组通信系统
复制系统(Replication systems)
核心
在多个副本(replicas)之间保持一致性(consistency),同时提高可用性(availability)和容错能力(fault tolerance)。
一致性模型
- 线性一致性(Linear Consistency/strict consistency): 读必须要返回最近一次写的内容,不管这个写是在哪出现的,所有的操作似乎是按照真实时间穿成一行。强度强,实现代价高。
- 顺序一致性(Sequential Consistency): 所有的操作可以排成一个合理的顺序(不违反因果律,结果正确),不要求全局保持正确顺序,只要求客户端内的操作不被打乱。强度较低,性能高。
系统组成
- 客户端(Client): 发起业务
- 前端(Front end/FE): 客户端的代理,提供接口,向后端发送请求,处理响应,协调系统的更新
- 复制管理(Replica manager): 存储数据的服务器,执行相关操作,协调一致性,回复FE的请求
这是一个最基本的模型: 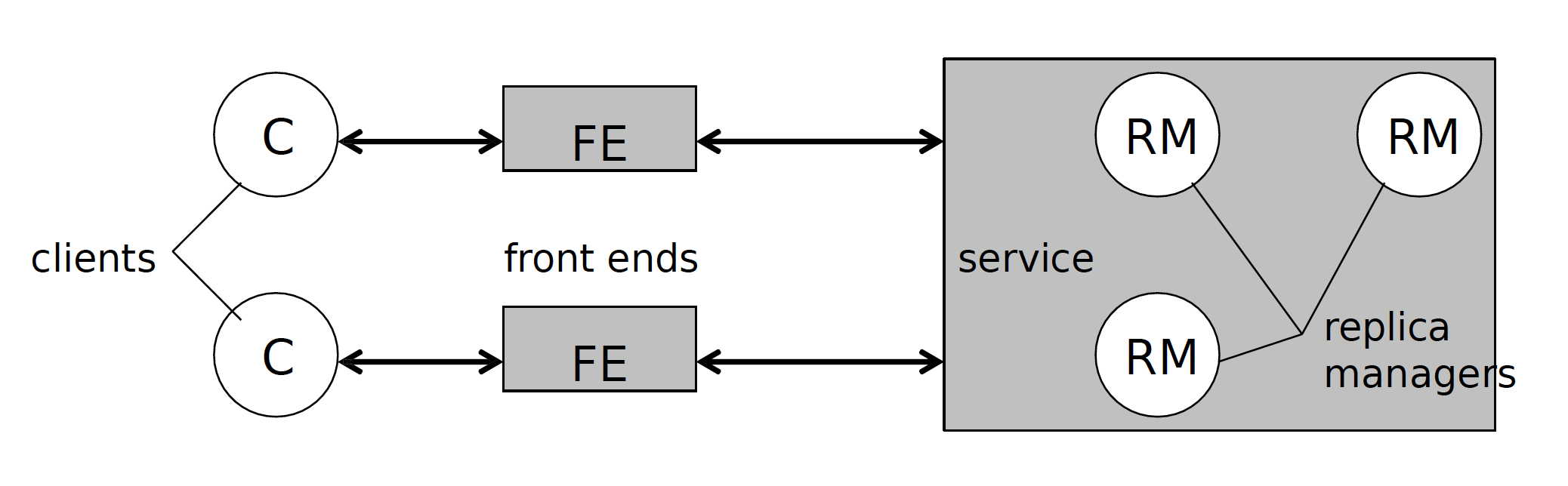
请求步骤
一次请求通常包含五个步骤:
- 请求(Request):FE 向一个或多个 RM 发送请求
- 协调(Coordination):RMs 协调是否执行 & 执行顺序,决定请求排序的级别
- 执行(Execution):RMs 执行操作(可能是暂时的)
- 保证结果(Agreement):RMs 对结果达成一致
- 返回请求(Response):向 FE / Client 返回结果
复制系统类型
被动复制(passive replication)
核心思想:
- 一个主副本(primary),多个备份副本。
- 所有请求走主副本,主副本处理完操作之后通知备份更新。
- 如果主副本挂了,则选取一个备份副本成为新的主副本。
- FE的要求是在发现当前的主节点不可用时可以自己定位到新主节点。
- 线性一致性
优点: 所有操作都走主节点,线性一致很容易实现。简单
缺点:主副本一个机子会成为整个系统的瓶颈。组通信开销大。
容错要求: 容忍f个崩溃需要f+1个RM。
变种:客户端可以从备份RM读取文件,但是此时一致性降为顺序一致性。
主动复制(active replication)
核心思想:
- 所有 RM 地位相同
- FE 将请求 可靠 多播 给所有 RM,
- 所有 RM 独立但以相同顺序执行
- FE将等待消息响应之后再发送下一个请求
- 顺序一致性
流程:
- 请求:FE 多播请求(带唯一 ID)
- 协调:所有 RM 按相同顺序收到请求
- 执行:所有 RM 执行(所有的RM都是状态机执行顺序也一样,因此结果都是相同的)
- 不需要保证结果,前面已经保证了是一致的: RM 回复 FE (带唯一ID)
- FE 决定用哪个结果(首个 / 多数)
优点:没有单点瓶颈,节点失效几乎不影响性能。
案例:gossip架构
老师好像说案例不考,但是我不是很确定,反正看看得了
核心思想
- 数据在多个RM之间复制, 数据更新通过RM间周期性交换Gossip消息进行
- FE一致保持和一个RM之间的连接,直到那个RM出问题
- 操作到达一个RM之后立刻执行,数据的更新通过RM之间的信息交换慢慢同步
- 每个FE保有一个向量时间戳(vector timestamp)表,保存有每一个RM的最新向量时间戳
- 每次请求携带之前的时间戳,如果RM的时间戳比FE保有的新才能安全返回更改。
- 最终一致性:所有更新最终都会传播到所有 RM
- 客户端不会“读到比自己见过的更旧的数据”
RM内保有的状态:
1. Value
- 当前应用状态
- 状态机
2. Value Timestamp
- 当前 Value 已包含哪些更新
- 向量时间戳
3. Update Log
- 收到但未稳定的更新
- 等待因果条件满足
4. Executed Operation Table
- 已执行的更新 ID
- 防止同一 update 被执行两次
5. Timestamp Table
- 记录其他 RM 的进度
- 判断哪些更新已经“全局稳定”这个架构保证了高可用性和最终一致性。
安全!(Secutiry!)
分布式系统易受到攻击,因为:
- 资源共享(resource sharing):系统对外开放,容易被未授权访问
- 暴露的接口(exposed interfaces):服务接口必须对网络开放
- 不安全的网络(insecure networks):通信可能被监听或篡改
- 攻击者了解系统算法:分布式算法通常是公开的
想要保护资源就意味着要保护:
- 保护那个对资源执行操作的进程
- 保护在进程之间传递的消息
安全机制(Mechanism) vs 安全策略(Policy)
安全机制 -> 如:加密、锁, 防范:
- 未授权访问(黑客入侵)
- 恶意攻击(如病毒、恶意软件)
- 错误使用(合法用户的误操作)
安全策略 -> 什么时候可用,谁可用。
三大安全威胁 + 五个攻击方式
安全威胁:
- 泄露(Leakage):未授权获取信息
- 篡改(Tampering):未授权修改数据
- 破坏(Vandalism):不为获得什么东西,只为破坏系统运行
攻击方式:想要攻击一个系统,攻击者至少要可以访问一个通信渠道或者建立一个看起来像是授权的渠道
- 窃听(Eavesdropping):在未授权的情况下复制了一个消息
- 伪装(Masquerading):在自己没被授权的情况下使用别人的身份发消息
- 消息篡改(Message Tampering / MITM): 中间人攻击的一种,解密消息,更改内容再发过去
- 重放攻击(Replay):中间人攻击的一种,将某一个消息复制一份,一段时间后再发一遍
- 拒绝服务(DoS / DDoS):堵塞信道或者某个资源让其它人不能用
在了解了可能的威胁之后,我们就要设计一个安全的系统了
设计分布式系统
一个分布系统能面临的最坏的情况:
- 接口暴露
- 网络不安全
- 攻击者知道算法
- 攻击者资源充足
因此面对这种情况:
- 限制同一个密码和密钥的使用时间
- 最少可信基(Trusted Base): 最少化用来实现系统安全的组件
- 应用和数据分开,单独保护数据。
密码学
基本概念
- 加密(Encryption):明文 → 密文
- 解密(Decryption):密文 → 明文
- 密钥(Key):系统中唯一需要保密的部分
Kerckhoffs 原则: 系统应当在算法完全公开的情况下依然安全
三种加密方式
对称密钥加密(Symmetric Key)
- 加密和解密用同一个密钥(Shared Key)
- 快,但 密钥分发困难
- 两种加密方式:
- 流密码(Stream Cipher)
- 使用算法对一个密钥生成一个长的密钥流,然后对明文加密
- 分组密码(Block Cipher)
- 把明文切块,一块块用密文加密
- 流密码(Stream Cipher)
公钥密码(Public Key / Asymmetric)
- 公钥加密,私钥解密
- 解决密钥分发问题
- 基于陷门单向函数(Trapdoor Function):
单向指某一个方向好算,反着难算,比如大素数分解 . 公钥和私钥互为可逆运算,公钥(私钥(x)) = x,私钥(公钥(x)) = x
- 支持:
- 保密通信:公钥加密,只有拥有私钥的人才能解密
- 数字签名:私钥加密文件hash之后附带到文件上,公钥解密之后如果和文件hash对上了就说明文件是对的
哈希(Hash)
- 单向
- 常用于完整性校验
密码学用途(Uses of Cryptography)
- 保密性(Secrecy) 和 完整性(Integrity)
- 认证(Authentication)
- 数字签名(Digital Signatures)
密码学的应用(Applications of Cryptography)
- 数字证书(Digital Certificates)
- 访问控制(Access Control)
- 能力列表(Capabilities)
数字证书
数字证书是一个用来附带在信息上证明你是谁,由可信第三方签发的凭证。
最大问题:吊销(Revocation)
想要吊销一个证书,需要销毁所有这个证书的副本,但是这个证书实际上是附带在文件上的,而文件可复制。最简单的方式是设一个有效期。
主流标准:X.509
认证(Authentication) vs 授权(Authorization)
认证:你是谁? 授权:你能干这件事吗?是一种访问控制
在开始讲后面的安全模型之前,老师提到了政府过去试图规范化系统安全级别评估标准。某种意义上来说是授权的发展史。主要思想就是安全是分级的,有不同的安全级别。
传统视角里的授权:访问控制列表(ACLs) vs 能力列表(C-list)
访问控制矩阵(理论模型)
- 行:用户(Subjects)
- 列:资源(Objects)

ACL(Access Control List/访问控制列表)
- 按资源存权限(一列一列存)
- 数据导向,改资源权限方便

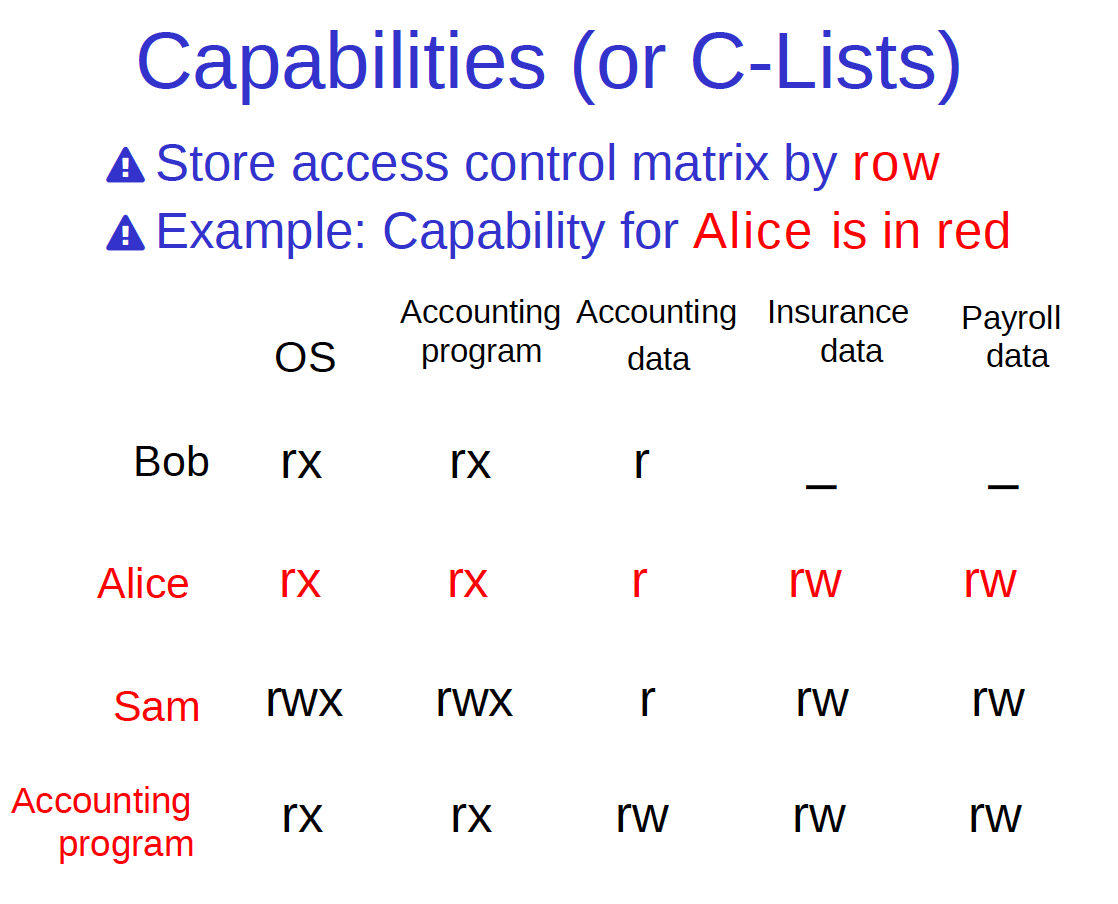
Capability(能力列表)**
- 按用户存权限(按行存)
- 易委派,避免误用权限
比如A用文件编辑器编辑文件,保存时选择系统目录,A无权编辑系统目录但是文件编辑器有权,这时候A就误用了编辑器的权限。
- 实现复杂
多层级安全模型(Multilevel Security (MLS) Models)
多级安全也是一种访问控制
- 对象有 安全级别 (Classification)
- 用户有 访问许可 (Clearance)
- 常见于军事/政府系统 老师这里讨论的是最简单的模型,而不是实际实现的MLS模型
Bell–LaPadula(BLP)
最基本的MLS需求
- 关注保密性(confidentiality): 防止非认证的读
Biba 模型
- 关注完整性(integrity):防止非认证的写
- 是 BLP 的“对偶模型”
这里老师就是超级简略